auswahl.MCUVE¶
- class auswahl.MCUVE(n_features_to_select: Optional[Union[int, float]] = None, n_subsets: int = 100, n_samples_per_subset: Optional[Union[int, float]] = None, pls: Optional[PLSRegression] = None, n_cv_folds: int = 5, model_hyperparams: Optional[Union[Dict, List[Dict]]] = None, random_state: Optional[Union[int, RandomState]] = None)[source]¶
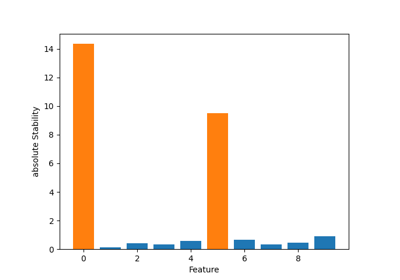
Feature selection with Monte Carlo Uninformative Variable Elimination.
The stability for each feature is computed according to Cai et al. [1].
Note that the absolute stability values are used to determine the most important features.
Read more in the User Guide.
- Parameters
- n_features_to_selectint or float, default=None
Number of features to select.
- n_subsetsint, default=100
Number of random subsets to create.
- n_samples_per_subsetint or float, default=None
Number of samples used for each random subset.
- plsPLSRegression, default=None
Estimator instance of the
PLSRegressionclass. Use this to adjust the hyperparameters of the PLS method.- random_stateint or numpy.random.RandomState, default=None
Seed for the random subset sampling. Pass an int for reproducible output across function calls.
- Attributes
- coefs_ndarray of shape (n_subsets, n_features)
Fitted regression coefficients of the <n_subsets> PLS models.
- stability_ndarray of shape (n_features,)
Computed stability value for each feature. While these attribute contains the signed stability values, MC-UVE uses the absolute values to select the most important features.
- support_ndarray of shape (n_features,)
Mask of selected features.
References
- 1
Wensheng Cai, Yankun Li and Xueguang Shao, ‘A variable selection method based on uninformative variable elimination for multivariate calibration of near-infrared spectra’, Chemometrics and Intelligent Laboratory Systems, 90, 188-194, 2008.
Examples
>>> import numpy as np >>> from auswahl import MCUVE >>> X = np.random.randn(100, 10) >>> y = 5 * X[:, 0] - 2 * X[:, 5] # y only depends on two features >>> selector = MCUVE(n_features_to_select=2) >>> selector.fit(X, y).get_support() array([ True, False, False, False, False, True, False, False, False, False])
- __init__(n_features_to_select: Optional[Union[int, float]] = None, n_subsets: int = 100, n_samples_per_subset: Optional[Union[int, float]] = None, pls: Optional[PLSRegression] = None, n_cv_folds: int = 5, model_hyperparams: Optional[Union[Dict, List[Dict]]] = None, random_state: Optional[Union[int, RandomState]] = None)[source]¶
- evaluate(X, y, model, do_cv=True, *args)¶
Conduct a cross validationand hyperparameter optimization of the underlying estimator model.
- Parameters
- X: array-like, shape (n_samples, n_features)
Spectral data to be fitted
- y: array-like, shape (n_samples,)
Regression targets
- model: BaseEstimator
Regression model
- do_cv: bool, default=True
If True, the model is fitted to the data and a cross validation score is provided
- *args: arbitrary payload
Arbitrary payload returned with the evaluation result. Used for instance for identification of threads, if multiple models are evaluated in parallel
- Returns
- tuple: float, BaseEstimator
cross validation score if requested (otherwise None) and fitted estimator
- fit(X, y, mask=None)¶
Run the feature selection process.
- Parameters
- Xarray-like of shape (n_samples, n_features)
The input samples.
- yarray-like of shape (n_samples,)
The target values.
- mask: array-like of shape (n_features,)
Mask indicating (values == 0), which features are not to be taken into account during the feature selection
- Returns
- SpectralSelectorself
Returns the instance itself.
- fit_transform(X, y=None, **fit_params)¶
Fit to data, then transform it.
Fits transformer to X and y with optional parameters fit_params and returns a transformed version of X.
- Parameters
- Xarray-like of shape (n_samples, n_features)
Input samples.
- yarray-like of shape (n_samples,) or (n_samples, n_outputs), default=None
Target values (None for unsupervised transformations).
- **fit_paramsdict
Additional fit parameters.
- Returns
- X_newndarray array of shape (n_samples, n_features_new)
Transformed array.
- get_best_estimator() BaseEstimator¶
Retrieve the best estimator model fitted on the selected features
- Returns
- best model fitted on selected features: sklearn.base.BaseEstimator
- get_feature_names_out(input_features=None)¶
Mask feature names according to selected features.
- Parameters
- input_featuresarray-like of str or None, default=None
Input features.
If input_features is None, then feature_names_in_ is used as feature names in. If feature_names_in_ is not defined, then the following input feature names are generated: [“x0”, “x1”, …, “x(n_features_in_ - 1)”].
If input_features is an array-like, then input_features must match feature_names_in_ if feature_names_in_ is defined.
- Returns
- feature_names_outndarray of str objects
Transformed feature names.
- get_params(deep=True)¶
Get parameters for this estimator.
- Parameters
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns
- paramsdict
Parameter names mapped to their values.
- get_support(indices=False)¶
Get a mask, or integer index, of the features selected.
- Parameters
- indicesbool, default=False
If True, the return value will be an array of integers, rather than a boolean mask.
- Returns
- supportarray
An index that selects the retained features from a feature vector. If indices is False, this is a boolean array of shape [# input features], in which an element is True iff its corresponding feature is selected for retention. If indices is True, this is an integer array of shape [# output features] whose values are indices into the input feature vector.
- inverse_transform(X)¶
Reverse the transformation operation.
- Parameters
- Xarray of shape [n_samples, n_selected_features]
The input samples.
- Returns
- X_rarray of shape [n_samples, n_original_features]
X with columns of zeros inserted where features would have been removed by
transform().
- reseed(seed: Union[int, RandomState])¶
Random state updating interface for benchmarking. Selector methods with more complex internal structure (such as methods wrapping other methods) are required to override this function accordingly.
- rethread(n_jobs: int)¶
n_jobs updating interface for benchmarking. Selector methods with more complex internal structure (such as methods wrapping other methods) are required to override this function accordingly.
- set_params(**params)¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters
- **paramsdict
Estimator parameters.
- Returns
- selfestimator instance
Estimator instance.
- transform(X)¶
Reduce X to the selected features.
- Parameters
- Xarray of shape [n_samples, n_features]
The input samples.
- Returns
- X_rarray of shape [n_samples, n_selected_features]
The input samples with only the selected features.